ES详解 - ES字段类型
ES详解 - ES字段类型
在学习 ES 文档相关操作之前,我们先学习 ES 中常用的字段类型。
1. 字段类型
1.1 text
当一个字段的内容需要被全文检索时,可以使用text类型,
优点
支持长内容的存储,比如检索文章内容、商品信息等。
该类型的字段内容在保存时会被分词器分析,并且拆分成多个词项
然后根据拆分后的词项生成对应的索引,根据关键字检索时可能会将关键字分词,用分好的词从之前生成的索引中去匹配,进而找到对应的文档。
局限性
- 对于
text类型的字段你可能无法通过指定文本精确的检索到。 - 另外需要注意的是,
text类型的字段不能直接用于排序、聚合操作。
这种类型的字符串也称做analyzed字符串。
1.2 keyword
keyword类型适用于结构化的字段,比如手机号、商品id、用户id等,默认最大长度为256。
keyword类型的字段内容不会被分词器分析、拆分,而是根据原始文本直接生成倒排索引,所以keyword类型的字段可以直接通过原始文本精确的检索到。keyword类型的字段可用于过滤、排序、聚合操作。
这种字符串称做not-analyzed字符串。
1.3 日期类型
ES 中的date类型默认支持如下两种格式:
strict_date_optional_time,表示 yyyy-MM-dd'T'HH:mm:ss.SSSSSSZ 或者 yyyy-MM-dd 格式的日期epoch_millis,表示从 1970.1.1 零点到现在的毫秒数,
如果我们要存储类似2020-12-01 20:10:15这种格式的日期就会有问题,我们可以在创建索引时指定字段为date类型以及可以匹配的日期格式:
PUT blog
{
"mappings": {
"properties": {
"publishDate":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
需要注意的是,如果不主动指定字段类型为date,ES 默认使用text类型去保存日期的值。
1.4 布尔类型
boolean类型就简单了,有true、false两个值。
1.5 数值类型
| 类型 | 取值范围 |
|---|---|
| byte | -2^7 ~ 2^7-1 |
| short | -2^15 ~ 2^15-1 |
| integer | -2^31 ~ 2^31-1 |
| long | -2^63 ~ 2^63-1 |
| float | 32位单精度IEEE 754浮点类型 |
| double | 64位双精度IEEE 754浮点类型 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数 |
一般情况下,如果可以满足需求,则优先使用范围小的类型,来提高效率。
1.6 数组类型
其实在 ES 中并没有数组类型,但我们却可以按数组格式来存储数据,因为 ES 中默认每个字段可以包含多个值,同时要求多个值得类型必须一致。例如可以按照如下方式指定一个字段的值为数组:
"label": [
"Elastcsearch",
"7.9.3版本"
]
1.7 对象类型
这个其实没什么特别的,由于 ES 中以 JSON 格式存储数据,所以一个 JSON 对象中的某个字段值可以是另一个 JSON 对象。
1.8 范围类型
| 类型 | 技能 |
|---|---|
| integer_range | -2^31 ~ 2^31-1 |
| long_range | -2^63 ~ 2^63-1 |
| float_range | 32位单精度IEEE 754浮点类型 |
| double_range | 64位双精度IEEE 754浮点类型 |
| date_range | 自系统历元以来无符号64位整数范围内的毫秒数 |
| ip_range | IPv4、IPv6 的一系列IP地址值 |
例如我们可以创建索引时定义一个日期范围的字段类型:
PUT blog
{
"mappings": {
"properties": {
"reader_age_range":{
"type": "integer_range"
}
}
}
}
添加文档时可以这样指定字段的值:
"reader_age_range": {
"gte": 10,
"lte": 50
}
2. 数组类型与嵌套数据类型
2.1 开箱即用的数组类型
在ElasticSearch中,没有专门的数组(Array)数据类型,但是,在默认情况下,任意一个字段都可以包含0或多个值,这意味着每个字段默认都是数组类型,只不过,数组类型的各个元素值的数据类型必须相同。在ElasticSearch中,数组是开箱即用的(out of box),不需要进行任何配置,就可以直接使用。
2.1.1 数组类型
在同一个数组中,数组元素的数据类型是相同的,ElasticSearch不支持元素为多个数据类型:[ 10, "some string" ],常用的数组类型是:
- 字符数组: [ "one", "two" ]
- 整数数组: productid:[ 1, 2 ]
- 对象(文档)数组: "user":[ { "name": "Mary", "age": 12 }, { "name": "John", "age": 10 }],ElasticSearch内部把对象数组展开为
对于文档数组,每个元素都是结构相同的文档,文档之间都不是独立的,在文档数组中,不能独立于其他文档而去查询单个文档,这是因为,一个文档的内部字段之间的关联被移除,各个文档共同构成对象数组。
对整数数组进行查询,例如,使用多词条(terms)查询类型,查询productid为1和2的文档:
{
"query":{
"terms":{
"productid":[ 1, 2 ]
}
}
}
2.1.2对象数组
通过PUT动词,自动创建索引和文档类型,在文档中创建对象数组:
PUT my_index/my_type/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
ElasticSearch引擎内部把对象数组展开成扁平的数据结构,把上例的文档类型的数据结构展开之后,文档数据类似于:
{
"group" : "fans",
"user.first" : [ "alice", "john" ],
"user.last" : [ "smith", "white" ]
}
字段 user.first 和 user.last 被展开成数组字段,但是,这样展开之后,单个文档内部的字段之间的关联就会丢失,在该例中,展开的文档数据丢失first和last字段之间的关联,比如,Alice 和 white 的关联就丢失了。
2.2 嵌套数据类型
嵌套数据类型是对象数据类型的特殊版本,它允许对象数组中的各个对象被索引,数组中的各个对象之间保持独立,能够对每一个文档进行单独查询
嵌套数据类型是对象数据类型的特殊版本,
- 它允许对象数组中的各个对象被索引
- 数组中的各个对象之间保持独立,能够对每一个文档进行单独查询
这就意味着,嵌套数据类型保留文档的内部之间的关联,ElasticSearch引擎内部使用不同的方式处理嵌套数据类型和对象数组的方式,对于嵌套数据类型,ElasticSearch把数组中的每一个嵌套文档(Nested Document)索引为单个文档,这些文档是隐藏(Hidden)的,文档之间是相互独立的,但是,保留文档的内部字段之间的关联,使用嵌套查询(Nested Query)能够独立于其他文档而去查询单个文档。在创建嵌套数据类型的字段时,需要设置字段的type属性为nested。
2.2.1 在索引映射中创建嵌套字段
设置user字段为嵌套数据类型,由于每个字段默认都可以是数组类型,因此,嵌套字段也可以是对象数组。
"mappings":{
"my_type":{
"properties":{
"group":{ "type":"string"},
"user":{
"type":"nested",
"properties":{
"first":{ "type":"string"},
"second":{ "type":"string"}
}
}
}
}
}
2.2.2 为嵌套字段赋值
为嵌套字段赋予多个值,那么ElasticSearch自动把字段值转换为数组类型。
PUT my_index/my_type/1
{
"group" : "fans",
"user" : [
{ "first" : "John", "last" : "Smith"},
{ "first" : "Alice", "last" : "White"}
]
}
在ElasticSearch内部,嵌套的文档(Nested Documents)被索引为很多独立的隐藏文档(separate documents),这些隐藏文档只能通过嵌套查询(Nested Query)访问。每一个嵌套的文档都是嵌套字段(文档数组)的一个元素。嵌套文档的内部字段之间的关联被ElasticSearch引擎保留,而嵌套文档之间是相互独立的。在该例中,ElasticSearch引起保留Alice和White之间的关联,而John和White之间是没有任何关联的。
默认情况下,每个索引最多创建50个嵌套文档,可以通过索引设置选项:index.mapping.nested_fields.limit 修改默认的限制。
Indexing a document with 100 nested fields actually indexes 101 documents as each nested document is indexed as a separate document.
2.3 easy-es中的嵌套类型
2.3.1 前言
ES底层是Lucene,由于Lucene实际上是不支持嵌套类型的,所有文档都是以扁平的结构存储在Lucene中,ES对嵌套文档的支持,实际上也是采取了一种投机取巧的方式实现的.
嵌套的文档均以独立的文档存入,然后添加关联关系,这就会导致,一条嵌套类型的文档,底层实际上存储了N条数据,而且更新时会株连九族式更新,导致效率低下,而且对于嵌套类型,其查询功能也受限,不支持聚合排序等功能,因此我们并不建议您在实际开发中使用这种类型.
ES本身更适合"大宽表"模式,不要带着传统关系型数据库那种思维方式去使用ES,我们完全可以通过把多张表中的字段和内容合并到一张表(一个索引)中,来完成期望功能,尽可能规避嵌套类型的使用,不仅效率高,功能也更强大.
当然存在即合理,也确实有个别场景下,不可避免的会用到嵌套类型,作为全球首屈一指的ES-ORM框架,我们对此也提供了支持,用户可以不用,但我们不能没有!
2.3.2 嵌套类型创建索引
- 自动挡模式:
public class Document{
// 省略其它字段...
/**
* 嵌套类型
*/
@IndexField(fieldType = FieldType.NESTED, nestedClass = User.class)
private List<User> users;
}
注意
务必像上面示例一样指定类型为fieldType=NESTED及其nestedClass,否则会导致框架无法正常运行
3. 示例
最后我们通过一个完整的例子梳理一下这些字段类型,首先创建blog索引,并指定相关字段的类型:
3.1 建索引
PUT blog
{
"mappings": {
"properties": {
"publishDate": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"reader_age_range": {
"type": "integer_range"
}
}
}
}
3.2 添加文档数据
然后添加一条文档数据:
POST blog/_doc
{
"title": "Learn Elastcsearch",
"publishDate": "2020-12-01 20:10:15",
"isTop": true,
"score": 4.5,
"commnetNum": 50,
"label": [
"Elastcsearch",
"7.9.3版本"
],
"author": {
"name": "shehuan",
"github": "https://github.com/shehuan"
},
"reader_age_range": {
"gte": 10,
"lte": 50
}
}
3.3 说明
上边我们只指定了publishDate和reader_age_range字段的类型,其它的并未指定。其实在添加文档时,ES 也会根据字段的值动态的推断出它的类型,即动态映射,但这样可能出现推断不符合预期的问题,例如前边说过的日期类型,所以你可以根据实际情况选择是否主动指定字段的类型。
3.4 查看文档mapping信息
再使用如下请求查看一下文档字段的mapping信息:
GET blog/_mapping?pretty
结果如下:
{
"blog" : {
"mappings" : {
"properties" : {
"author" : {
"properties" : {
"github" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"commnetNum" : {
"type" : "long"
},
"isTop" : {
"type" : "boolean"
},
"label" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"publishDate" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"reader_age_range" : {
"type" : "integer_range"
},
"score" : {
"type" : "float"
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
由于我们未指定title字段的类型, ES 自动将其映射成了text类型,同时还添加了一个类型为keyword的字段:
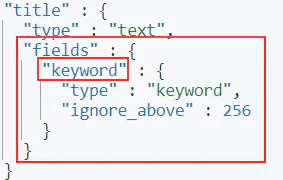
这意味着,我们可以使用title.keyword的方式将title字段当做keyword类型去使用。