ES框架 - Easy-Es中的注意点
ES框架 - Easy-Es中的注意点
1. ES索引的keyword类型和text类型
ES中的keyword类型,和MySQL中的字段基本上差不多,当我们需要对查询字段进行精确匹配,左模糊,右模糊,全模糊,排序聚合等操作时,需要该字段的索引类型为keyword类型,否则你会发现查询没有查出想要的结果,甚至报错. 比如EE中常用的API eq(),like(),distinct()等都需要字段类型为keyword类型.
当我们需要对字段进行分词查询时,需要该字段的类型为text类型,并且指定分词器(不指定就用ES默认分词器,效果通常不理想). 比如EE中常用的API match()等都需要字段类型为text类型. 当使用match查询时未查询到预期结果时,可以先检查索引类型,然后再检查分词器,因为如果一个词没被分词器分出来,那结果也是查询不出来的.
当同一个字段,我们既需要把它当keyword类型使用,又需要把它当text类型使用时,此时我们的索引类型为keyword_text类型,EE中可以对字段添加注解@TableField(fieldType = FieldType.KEYWORD_TEXT),如此该字段就会被创建为keyword+text双类型如下图所示,值得注意的是,当我们把该字段当做keyword类型查询时,ES要求传入的字段名称为"字段名.keyword",当把该字段当text类型查询时,直接使用原字段名即可.
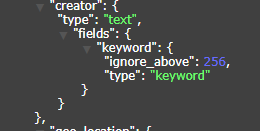
另一种做法是,可以冗余一个字段,值用相同的,一个注解标记为keyword类型,另一个标记为text类型,查询时按规则选择对应字段进行查询.
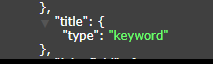
还需要注意的是,如果一个字段的索引类型被创建为仅为keyword类型(如下图所示)查询时,则不需要在其名称后面追加.keyword,直接查询就行.
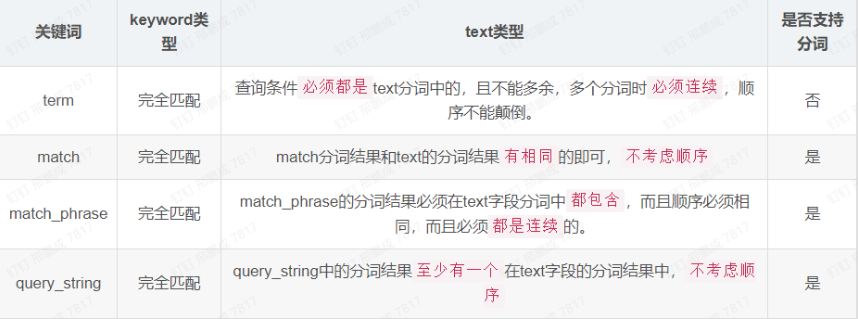
2. termQuery,match,match_phrase区别
3. EE在整个查询过程中做了什么?
总结起来就2件:
- 把用户输入的MySQL语法(Mybatis-Plus语法)转换成RestHighLevel语法,然后调用RestHighLevelClient执行本次查询
- 把查询结果转换成用户想要的格式:如
List<T>并返回.
4. 索引处理
模式一:自动托管之平滑模式(自动挡-雪地模式) 默认开启此模式
在此模式下,索引的创建更新数据迁移等全生命周期用户均不需要任何操作即可完成,过程零停机,用户无感知,可实现在生产环境的平滑过渡,类似汽车的自动档-雪地模式,平稳舒适,彻底解放用户,尽情享受自动架势的乐趣! 需要值得特别注意的是,在自动托管模式下,系统会自动生成一条名为ee-distribute-lock的索引,该索引为框架内部使用,用户可忽略,若不幸因断电等其它因素极小概率下发生死锁,可删除该索引即可.另外,在使用时如碰到索引变更,原索引名称可能会被追加后缀_s0或_s1,不必慌张,这是全自动平滑迁移零停机的必经之路,索引后缀不影响使用,框架会自动激活该新索引.关于_s0和_s1后缀,在此模式下无法避免,因为要保留原索引数据迁移,又不能同时存在两个同名索引,凡是都是要付出代价的,如果您不认可此种处理方式,可继续往下看,总有一种适合您。
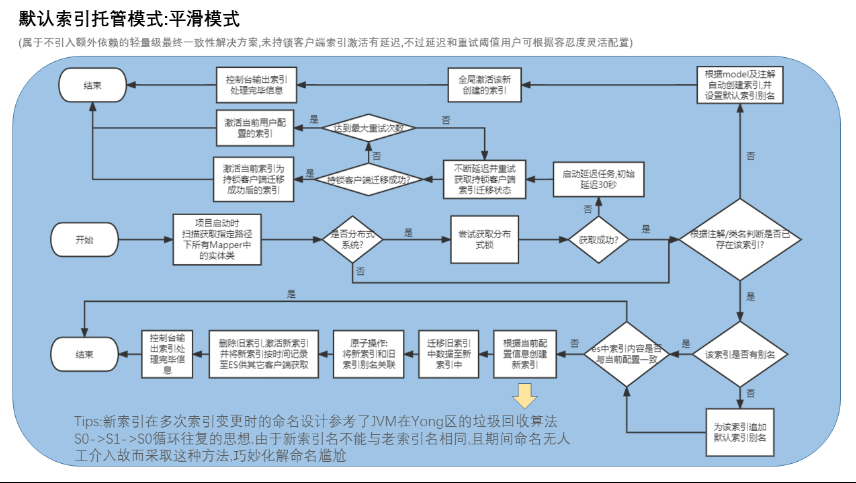
其核心处理流程梳理如下图所示,不妨结合源码看,更容易理解:
"自动挡"模式下的最佳实践示例:
@Data
@IndexName(shardsNum = 3,replicasNum = 2) // 可指定分片数,副本数,若缺省则默认均为1
public class Document {
/**
* es中的唯一id,如果你想自定义es中的id为你提供的id,比如MySQL中的id,请将注解中的type指定为customize,如此id便支持任意数据类型)
*/
@IndexId(type = IdType.CUSTOMIZE)
private Long id;
/**
* 文档标题,不指定类型默认被创建为keyword类型,可进行精确查询
*/
private String title;
/**
* 文档内容,指定了类型及存储/查询分词器
*/
@HighLight(mappingField="highlightContent")
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
private String content;
/**
* 作者 加@TableField注解,并指明strategy = FieldStrategy.NOT_EMPTY 表示更新的时候的策略为 创建者不为空字符串时才更新
*/
@IndexField(strategy = FieldStrategy.NOT_EMPTY)
private String creator;
/**
* 创建时间
*/
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private String gmtCreate;
/**
* es中实际不存在的字段,但模型中加了,为了不和es映射,可以在此类型字段上加上 注解@TableField,并指明exist=false
*/
@IndexField(exist = false)
private String notExistsField;
/**
* 地理位置经纬度坐标 例如: "40.13933715136454,116.63441990026217"
*/
@IndexField(fieldType = FieldType.GEO_POINT)
private String location;
/**
* 图形(例如圆心,矩形)
*/
@IndexField(fieldType = FieldType.GEO_SHAPE)
private String geoLocation;
/**
* 自定义字段名称
*/
@IndexField(value = "wu-la")
private String customField;
/**
* 高亮返回值被映射的字段
*/
private String highlightContent;
}
5. 分页查询
关于分页,我们支持了ES的三种分页模式,大家可参考下表,按需选择.
| 分页方式 | 性能 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| from+size 浅分页 | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll 滚动查询 | 中 | 解决了深度分页问题 | 无法反应数据的实时性 | 海量数据的导出需要查询海量结果集的数据 |
| search_after | 高 | 性能最好,不存在深度分页问题,能够反应数据的实时变化 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果,它不适用于大幅度跳页查询 | 海量数据的分页 |
5.1 浅分页
// 物理分页
EsPageInfo<T> pageQuery(LambdaEsQueryWrapper<T> wrapper, Integer pageNum, Integer pageSize);
温馨提示
无需集成任何插件,即可使用分页查询,本查询属于物理分页,基于size+from的浅分页模式,适用于查询数据量少于1万的情况,如您需要 在一些高阶语法的使用场景中,目前已知的有聚合字段的返回,我们分页器尚不能支持,需要您自己封装分页,其它场景基本都能完美支持,用起来无比简单. 注意PageInfo是由本框架提供的,如果你项目中已经有目前最受欢迎的开源分页插件PageHelper,请在引入包的时候注意别引入错误了,EE采用和PageHelper一样的返回字段,您无需担心字段名称不统一带来的额外工作量.
使用示例:
@Test
public void testPageQuery() {
LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();
wrapper.match(Document::getTitle, "老汉");
EsPageInfo<Document> documentPageInfo = documentMapper.pageQuery(wrapper,1,10);
System.out.println(documentPageInfo);
}
5.2 滚动查询
// 滚动查询
SearchResponse scroll(SearchScrollRequest searchScrollRequest, RequestOptions requestOptions) throws IOException;
提示
若您有需要进行超大量的数据查询和分页需求,可以采用滚动查询来实现,关于滚动查询,我们实际上已经提供了getSearchSourceBuilderAPI用于快速构造出SearchSourceBuilder,配合上面提供的滚动查询API,助力您快速实现滚动查询 当然我们更建议您使用下面searchAfter方式分页,不仅API封装得更好,使用更简单,而且具有其它天然优势。
5.3 searchAfter
使用示例:
@Test
public void testSearchAfter() {
LambdaEsQueryWrapper<Document> lambdaEsQueryWrapper = EsWrappers.lambdaQuery(Document.class);
lambdaEsQueryWrapper.size(10);
// 必须指定一种排序规则,且排序字段值必须唯一 此处我选择用id进行排序 实际可根据业务场景自由指定,不推荐用创建时间,因为可能会相同
lambdaEsQueryWrapper.orderByDesc(Document::getId);
SAPageInfo<Document> saPageInfo = documentMapper.searchAfterPage(lambdaEsQueryWrapper, null, 10);
// 第一页
System.out.println(saPageInfo);
Assertions.assertEquals(10, saPageInfo.getList().size());
// 获取下一页
List<Object> nextSearchAfter = saPageInfo.getNextSearchAfter();
SAPageInfo<Document> next = documentMapper.searchAfterPage(lambdaEsQueryWrapper, nextSearchAfter, 10);
Assertions.assertEquals(10, next.getList().size());
}
提示
使用searchAfter必须指定排序,若没有排序不仅会报错,而且对跳页也不友好. 需要保持searchAfter排序唯一,不然会导致分页失效,推荐使用id,uuid等进行排序.