数据库主键的一些思考
数据库主键的一些思考
1. 简介
对于分布式场景,主键自增会带来全局唯一性的问题。无疑采用雪花算法等是最合适分布式场景的。
但在若依框架中,并没有采用雪花算法。而是使用主键自增。并在git上作者这么说到
是呀,大部分人,大部分场景确实用不到。要改自己改也不是件难事
2. 用主键自增可以吗?
其实大部分场景我们一主多从读写分离就够用了。在只有一主写的情况下,自增完全是能解决我们的问题的。
作为框架再说,不用做的那么绝。如果真有需要自己去扩展就好了
3. 主键生成方案
3.1 主键自增的优缺点
3.1.1 优点:
1、数据存储空间小
2、查询效率高
3.1.2 缺点:
1、如果数据量过大,会超出自增长的值范围
2、分布式存储的表操作,尤其是在合并的时候操作复杂
3、安全性低,因为是有规律的,如果恶意扒取用户信息会很容易,如果是单据编号使用,竞争对手会容易查询出货量
3.2 使用UUID主键
3.2.1 优点:
1、出现重复的机会少
2、适合大量数据的插入和更新操作,尤其是在高并发和分布式环境下
3、安全性较高
3.2.2 缺点:
1、存储空间大(16 byte),因此它将会占用更多的磁盘空间, MySQL官方有明确的建议主键要尽量越短越好,36个字符长度的UUID不符合要求
2、性能降低,对MySQL索引不利: 如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
3.3 分布式环境下保证主键的唯一性
目前两种解决方式,下面分别介绍:
3.3.1 Twitter-Snowflake 64位自增id算法
背景:
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同
Snowflake算法核心
时间戳 + 工作机器id + 序列
Snowflake ID有64bits长 由如图4部分组成:
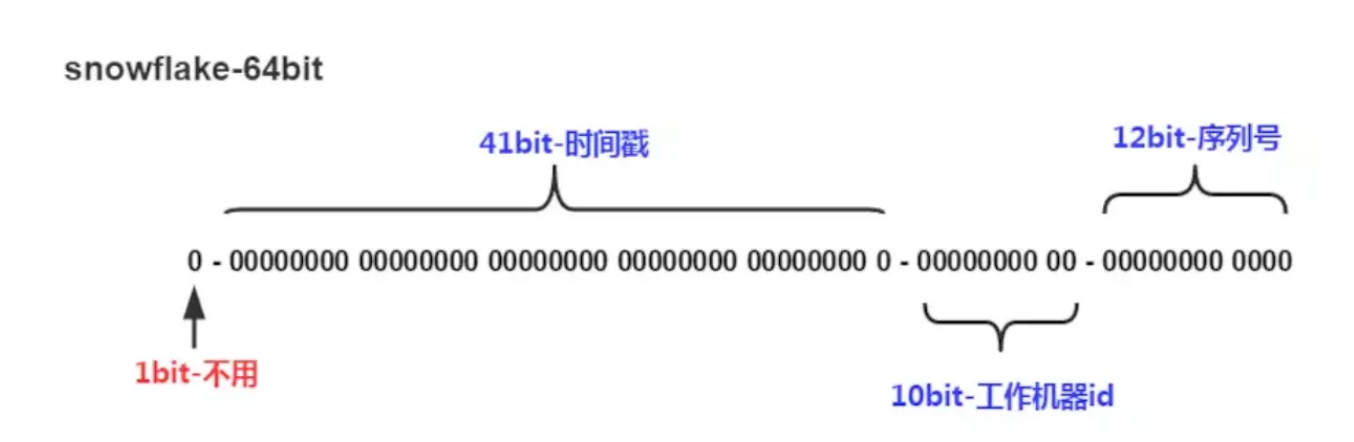
第一位不可用
第二组 timestamp—41bits 使用41位时间戳,精确到毫秒,意味着其可以表示长达(2^41-1)/(1000360024*365)=139.5年,另外使用者可以自己定义一个开始纪元(epoch),然后用(当前时间-开始纪元)算出time,这表示在time这个部分在140年的时间里是不会重复的,另外这里用time还有一个很重要的原因,就是可以直接更具time进行排序,对于twitter这种更新频繁的应用,时间排序就显得尤为重要了。
machine id—10bits(工作机器id),该部分其实由datacenterId和workerId两部分组成,这两部分是在配置文件中指明的:
10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId
1、datacenterId,方便搭建多个生成uid的service,并保证uid不重复,比如在datacenter0将机器0,1,2组成了一个生成uid的service,而datacenter1此时也需要一个生成uid的service,从本中心获取uid显然是最快最方便的,那么它可以在自己中心搭建,只要保证datacenterId唯一。如果没有datacenterId,即用10bits,那么在搭建一个新的service前必须知道目前已经在用的id,否则不能保证生成的id唯一,比如搭建的两个uid service中都有machine id为100的机器,如果其server时间相同,那么产生相同id的情况不可避免。
2、workerId是实际server机器的代号,最大到32,同一个datacenter下的workerId是不能重复的。它会被注册到consul上,确保workerId未被其他机器占用,并将host:port值存入,注册成功后就可以对外提供服务了。
- sequence id —12bits(序列号),该id可以表示4096个数字,它是在time相同的情况下,递增该值直到为0,即一个循环结束,此时便只能等到下一个ms到来,一般情况下4096/ms的请求是不太可能出现的,所以足够使用了。