Scrapy入门(四)-抓取AJAX异步加载网页
Scrapy入门(四)-抓取AJAX异步加载网页
1. 什么是AJAX?
AJAX即“Asynchronous Javascript And XML”(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术。
AJAX = 异步 JavaScript和XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
2. 两个Chrome插件
Toggle JavaScript
这个插件可以帮助我们快速直观地检测网页里哪些信息是通过AJAX异步加载而来的
JSON-handle
这个插件可以帮我们格式化Json串,从而让我们以一个更友好的方式查看Json内的信息。 chrome商店下载地址:https://chrome.google.com/webstore/detail/json-handle/iahnhfdhidomcpggpaimmmahffihkfnj
3. 分析过程(分析页面是否采用AJAX)
首先我们打开豆瓣电影分类排行榜 - 动作片栏目。

方案1:
如果网络慢,会看到影片列表在别的页面显示后才慢慢展示出来,试着把界面往下滑会不断有新的电影信息更新出来。 遇到这种情况初步就可以认定这个页面是采用AJAX异步加载的
方案2:
右键查看网页源码来鉴别。比如说你右键查看源码ctrl+f搜索这个杀手不太冷这几个字,你会发现源码里没有。
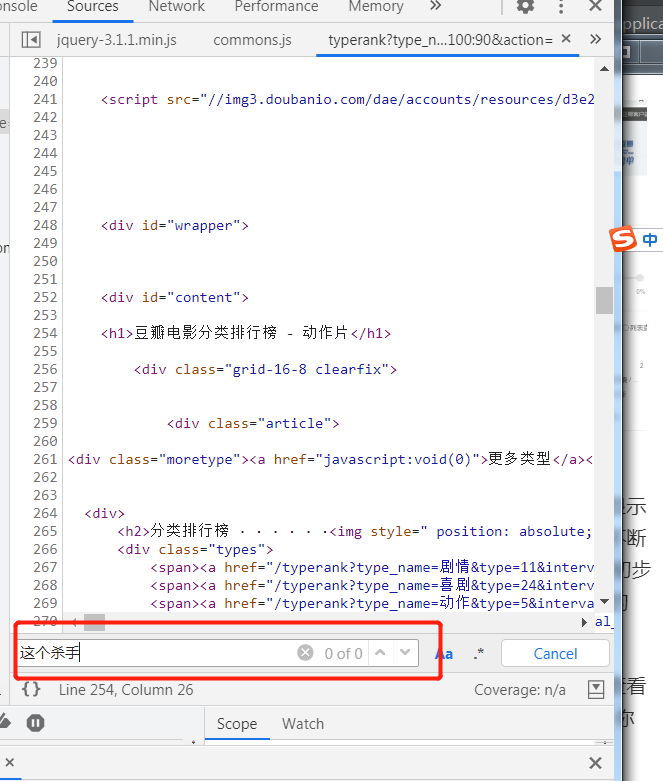
image-20210311152003444 方案3:
方案1和2,虽然能用,但是都不太方便,还记得上面推荐的那个chrome插件Toggle JavaScript吗?
image-20210311152349107 安好这个插件它就会出现在chrome浏览器的右边,试着轻轻点一下。
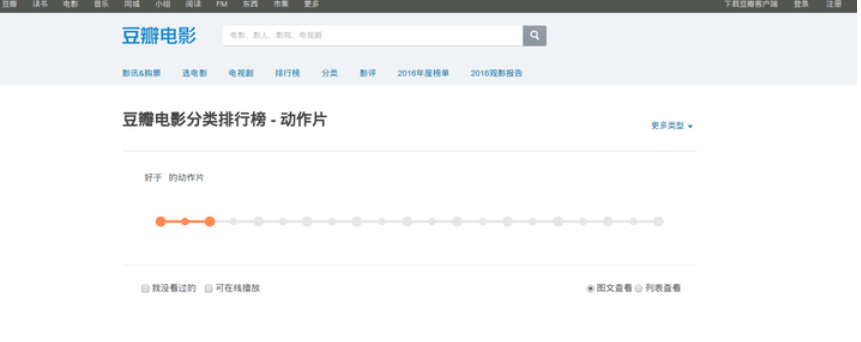
image-20210311152426689 刚才的电影信息都不见了!还记得AJAX的介绍吗?AJAX = 异步 JavaScript和XML。当我们点击了插件就代表这个我们封禁了JavaScript,这个页面里的JavaScript代码无法执行,那么通过AJAX异步加载而来的信息当然就无法出现了。通过这种方法我们能快速精确地知道哪些信息是异步加载而来的。
4. 如何抓取AJAX异步加载页面
对于这种网页我们一般会采用两种方法:
- 通过抓包找到AJAX异步加载的请求地址;
- 通过使用PhantomJS等无头浏览器执行JS代码后再对网页进行抓取。
通常情况下我会采用第一种方法,因为使用无头浏览器会大大降低抓取效率,而且第一种方法得到的数据格式往往以Json为主,非常干净。在这里我只讲解第一种方法,第二种方法作为爬虫的终极武器我会在后续的教程中进行讲解。 回到我们需要抓取的页面,还记得我说过页面的一个细节吗,下拉更新。进入页面后我们按F12打开chrome浏览器的开发者工具选择Network,然后实现一次下拉更新。
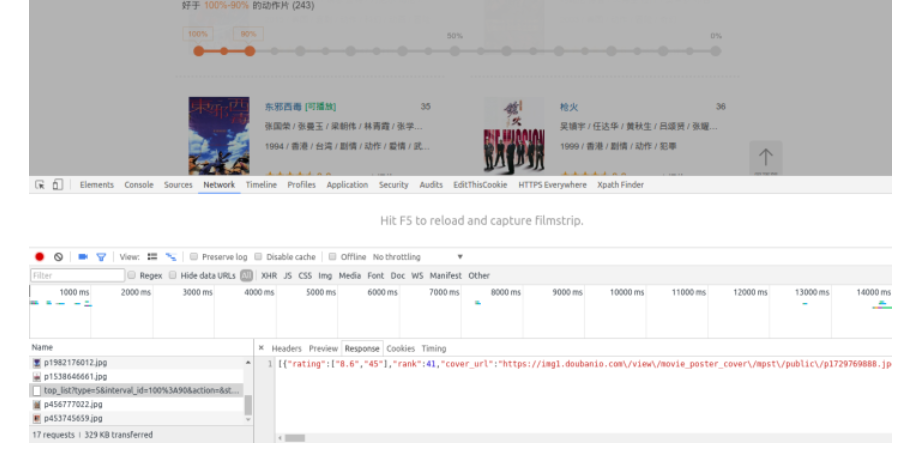
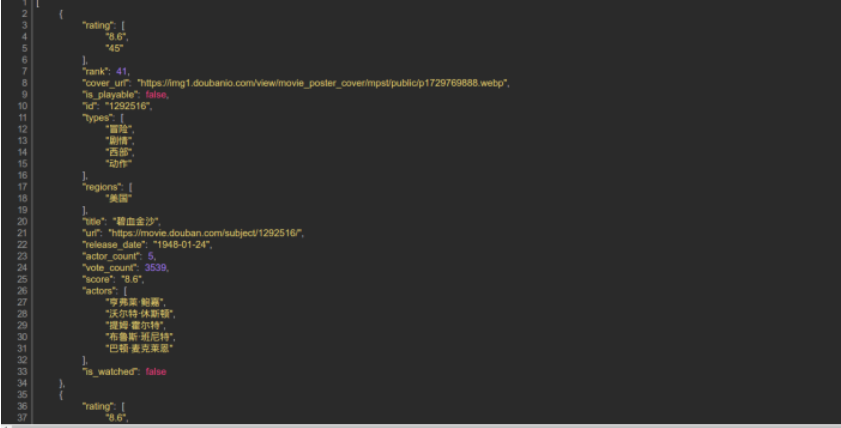
你会在Network里发现一个Response为Json格式的请求,仔细看看Json里的内容你会明白这些都是网页上显示的电影信息。右键该请求地址选择Open Link in New Tab,如果你装了JSON-handle插件你会以下面这种更友好的方式查看这个Json串。
接着再让我们看一该请求的Header信息
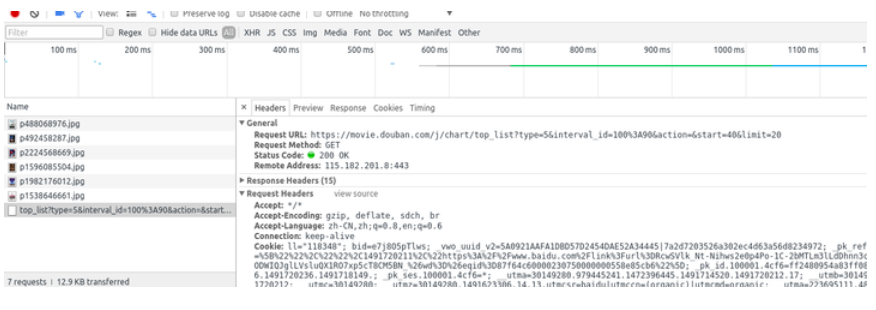
首先我们可以看出这是一个get请求,多看几个下拉请求的地址后你会发现地中的start=xxx在不断变化,每次增加20。所以我们只用更改这个参数就可以实现翻页不断获取新数据
# -*- coding: utf-8 -*-
# @Time : 2017/4/9 14:32
# @Author : woodenrobot
import re
import json
from scrapy import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanAJAXSpider(Spider):
name = 'douban_ajax'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
yield Request(url, headers=self.headers)
def parse(self, response):
datas = json.loads(response.body)
item = DoubanMovieItem()
if datas:
for data in datas:
item['ranking'] = data['rank']
item['movie_name'] = data['title']
item['score'] = data['score']
item['score_num'] = data['vote_count']
yield item
# 如果datas存在数据则对下一页进行采集
page_num = re.search(r'start=(\d+)', response.url).group(1)
page_num = 'start=' + str(int(page_num)+20)
next_url = re.sub(r'start=\d+', page_num, response.url)
yield Request(next_url, headers=self.headers)
在Scrapy工程文件的spiders里写好爬虫文件后在settings.py所在的目录下打开终端运行以下代码就能输出相应的电影数据。
scrapy crawl douban_ajax -o douban_movie.csv
5. 更好的查看json
点击JSON-handle 查看

image-20210311153418508 将JSON文本复制进来,点击确定
image-20210311153308124 查看结果
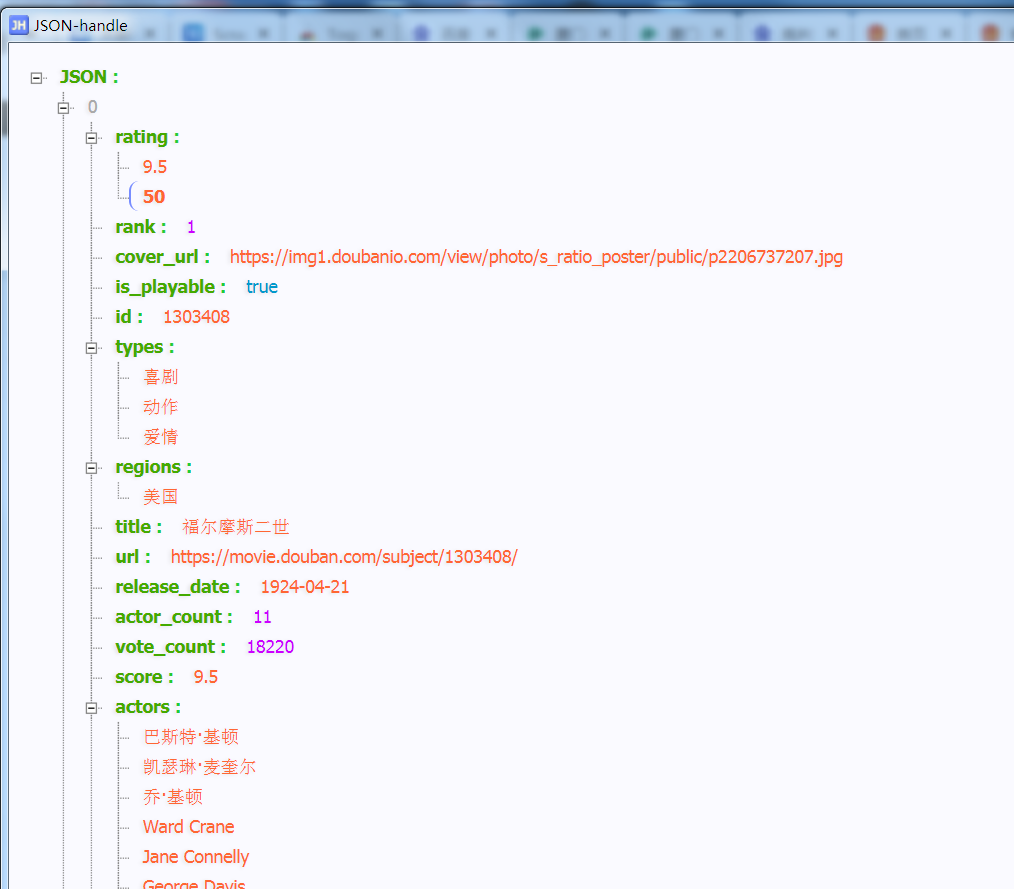
image-20210311153405800