MySQL - MySQL高可用-MHA方案
MySQL - MySQL高可用-MHA方案
1.简介
MHA是什么? MHA是由日本Mysql yoshinorim专家(原就职于DeNA现就职于FaceBook)用Perl写的一套Mysql故障切换方案,来保障数据库的高可用性,它的功能是能在10-30s之内实现主Mysql故障转移(failover),MHA故障转移可以很好的帮我们解决从库数据的一致性问题,同时最大化挽回故障发生后数据的一致性。 官方网站:https://code.google.com/p/mysql-master-ha/
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在10~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在较大程度上保证数据的一致性,以达到真正意义上的高可用。
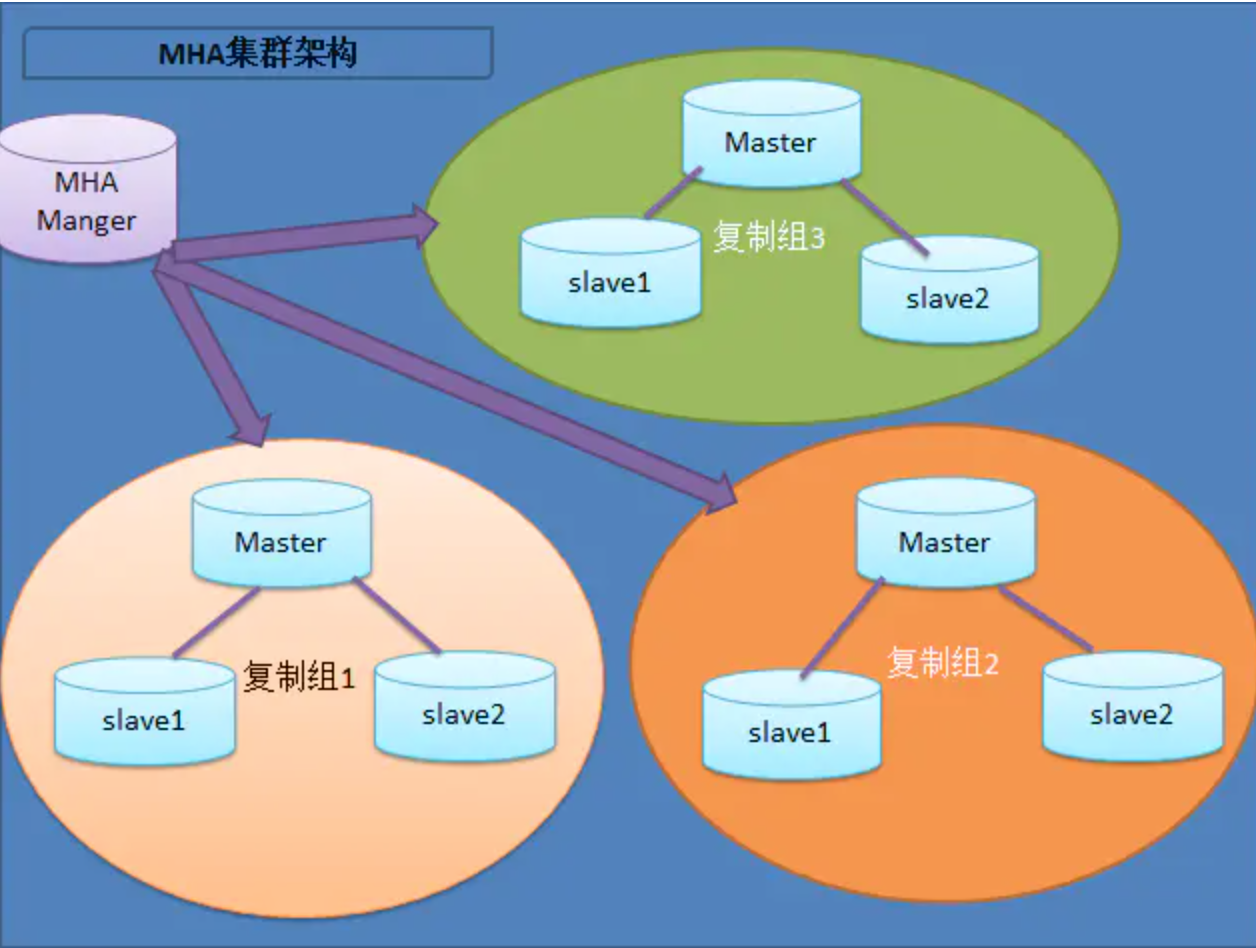
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,较大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了的二进制日志,MHA可以将的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
1.1.mha组件介绍
- MHA Manager 运行一些工具,比如masterha_manager工具实现自动监控MySQL Master和实现master故障切换,其它工具实现手动实现master故障切换、在线mater转移、连接检查等等。一个Manager可以管理多 个master-slave集群
- MHA Node 部署在所有运行MySQL的服务器上,无论是master还是slave。主要作用有三个。 1.保存二进制日志 如果能够访问故障master,会拷贝master的二进制日志 2.应用差异中继日志 从拥有最新数据的slave上生成差异中继日志,然后应用差异日志。 3.清除中继日志 在不停止SQL线程的情况下删除中继日志
1.2.背景和目标
在早期的MySQL架构中最主流就就是MySQL复制的主从结构,但伴随时间的推移以及数据的膨胀会出现一下几类问题。
以前几十台DB服务器,人工登陆服务器就能维护好,也没有高可用,当master挂了,通知业务将IP切换到slave然后重启也能基本满足业务要求,但是业务迅速发展,实例数不断增加,复制集不断增加,数据库架构多样化,而这种人工维护方式显然大大增加了DBA工作量,而且效率低下、容易出错。
DB规模的增大,机器故障、SQL故障、实例故障出现的概率也增加、还有来自业务方的DB变更,比如大表增加字段、增加索引、批量删除数据等异常维护操作,当然这些在一定条件下可用采用在线变更,比如采用pt-online-schema-change工具,但是当不满足在线变更条件、或者在线变更复杂的情况下,就需要采用滚动变更的方式,先在各个slave上变更、在线切换后再在master上变更,然后再进行一次切换还原,而这些切换操作如果全部手工敲命令来进行显然是不可取的。
随着用户数的不断增加,业务方对DB这种基础服务的可用性也就越来越高,在魅族业务对DB的可用性要求是每个月需要达到四个9,也就意味着每个月的故障时间只有不到5分钟,以前那种通知业务更改IP重启的方式显然是达不到这个要求的。
在这些背景和要求下,我们需要摆脱手工操作,需要一套有效的MySQL高可用方案和一个高效的高可用平台来支撑DB的快速增长。MySQL高可用平台需要达到的目标有以下几点:
- 数据一致性保证这个是最基本的同时也是前提,如果主备的数据的不一致,那么切换就无法进行,当然这里的一致性也是一个相对的,但是要做到最终一致性。
- 故障快速切换,当master故障时这里可以是机器故障或者是实例故障,要确保业务能在最短时间切换到备用节点,使得业务受影响时间最短。这里也可以指业务例行维护操作,比如前面提到的无法使用在线进行DDL的DDL操作,很多分表批量的DDL操作,这些操作通过在线切换方式来滚动完成。
- 简化日常维护,通过高可用平台来自动完成高可用的部署、维护、监控等任务,能够最大程度的解放DBA手动操作,提高日常运维效率。
- 统一管理,当复制集很多的情况下,能够统一管理高可用实例信息、实例信息、监控信息、切换信息等。
高可用的部署要对现有的数据库架构无影响,如果因为部署高可用,需要更改或者调整数据库架构则会导致成本增加。
2.MHA原理
2.1.MHA工作原理
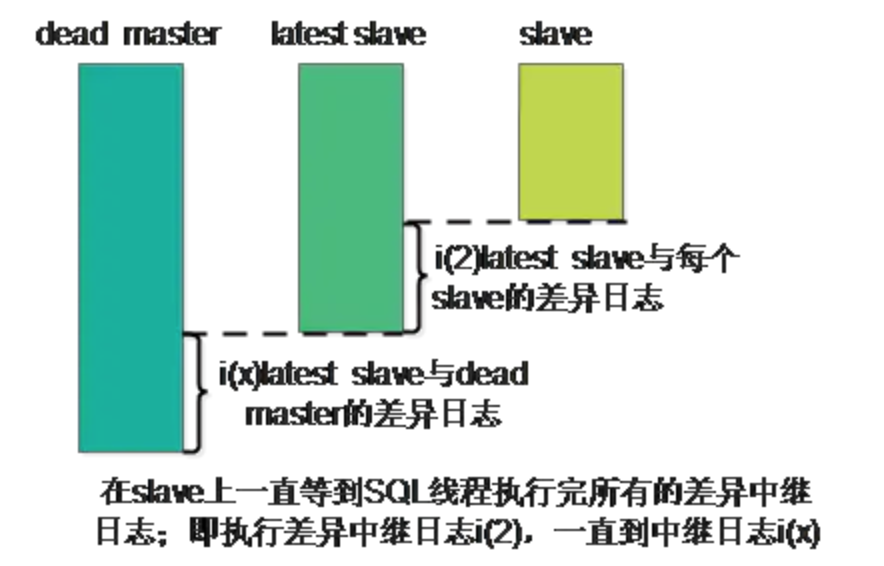
当master出现故障时,通过对比slave之间I/O线程读取masterbinlog的位置,选取最接近的slave做为latestslave。 其它slave通过与latest slave对比生成差异中继日志。在latest slave上应用从master保存的binlog,同时将latest slave提升为master。最后在其它slave上应用相应的差异中继日志并开始从新的master开始复制。
在MHA实现Master故障切换过程中,MHA Node会试图访问故障的master(通过SSH),如果可以访问(不是硬件故障,比如InnoDB数据文件损坏等),会保存二进制文件,以最大程度保 证数据不丢失。MHA和半同步复制一起使用会大大降低数据丢失的危险。流程如下:
- 从宕机崩溃的master保存二进制日志事件(binlog events)。
- 识别含有最新更新的slave。
- 应用差异的中继日志(relay log)到其它slave。
- 应用从master保存的二进制日志事件(binlog events)。
- 提升一个slave为新master并记录binlog file和position。
- 使其它的slave连接新的master进行复制。
- 完成切换manager主进程OFFLINE
2.2.MHA工具介绍
1.Manager工具:
- masterha_check_ssh : 检查MHA的SSH配置。
- masterha_check_repl : 检查MySQL复制。
- masterha_manager : 启动MHA。
- masterha_check_status : 检测当前MHA运行状态。
- masterha_master_monitor : 监测master是否宕机。
- masterha_master_switch : 控制故障转移(自动或手动)。
- masterha_conf_host : 添加或删除配置的server信息。
2. Node工具
- save_binary_logs : 保存和复制master的二进制日志。
- apply_diff_relay_logs : 识别差异的中继日志事件并应用于其它slave。
- filter_mysqlbinlog : 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)。
- purge_relay_logs : 清除中继日志(不会阻塞SQL线程)。 注意:Node这些工具通常由MHA Manager的脚本触发,无需人手操作。
2.3.当前高可用方案
- keepalived+mysql复制 该结构与MHA类似,但keepalived的优势在于无状态组件的故障切换,常用于web前端的故障转移,应用于数据库场景中,最致命的问题就是脑裂以后数据乱写的风险,为企业带来巨大困扰。
- MySQL Cluster MySQL Cluster真正实现了高可用,但是使用的是NDB存储引擎,并且SQL节点有单点故障问题。
- 半同步复制(5.5+) 半同步复制大大减少了“binlog events只存在故障master上”的问题。在提交时,保证至少一个slave(并不是所有的)接收到binlog,因此一些slave可能没有接收到binlog。
- PXC PXC实现了服务高可用,数据同步时是并发复制。但是仅支持InnoDB引擎,所有的表都要有主键。锁冲突、死锁问题相对较多等等问题。
2.4.MHA的优势
- 故障切换快 在 主从复制集群中,只要从库在复制上没有延迟,MHA通常可以在数秒内实现故障切换。9-10秒内检查到master故障,可以选择在7-10秒关闭 master以避免出现裂脑,几秒钟内,将差异中继日志(relay log)应用到新的master上,因此总的宕机时间通常为10-30秒。恢复新的master后,MHA并行的恢复其余的slave。即使在有数万台 slave,也不会影响master的恢复时间。 DeNA在超过150个MySQL(主要5.0/5.1版本)主从环境下使用了MHA。当mater故障后,MHA在4秒内就完成了故障切换。在传统的主动/被动集群解决方案中,4秒内完成故障切换是不可能的。
- master故障不会导致数据不一致 当 目前的master出现故障是,MHA自动识别slave之间中继日志(relay log)的不同,并应用到所有的slave中。这样所有的salve能够保持同步,只要所有的slave处于存活状态。和Semi- Synchronous Replication一起使用,(几乎)可以保证没有数据丢失。
- 需修改当前的MySQL设置 MHA的设计的重要原则之一就是尽可能地简单易用。MHA工作在传统的MySQL版本5.0和之后版本的主从复制环境中。和其它高可用解决方法比,MHA并不需要改变MySQL的部署环境。MHA适用于异步和半同步的主从复制。 启动/停止/升级/降级/安装/卸载MHA不需要改变(包扩启动/停止)MySQL复制。当需要升级MHA到新的版本,不需要停止MySQL,仅仅替换到新版本的MHA,然后重启MHA Manager就好了。 MHA运行在MySQL 5.0开始的原生版本上。一些其它的MySQL高可用解决方案需要特定的版本(比如MySQL集群、带全局事务ID的MySQL等等),但并不仅仅为了 master的高可用才迁移应用的。在大多数情况下,已经部署了比较旧MySQL应用,并且不想仅仅为了实现Master的高可用,花太多的时间迁移到不 同的存储引擎或更新的前沿发行版。MHA工作的包括5.0/5.1/5.5的原生版本的MySQL上,所以并不需要迁移。
- 无需增加大量的服务器 MHA由MHA Manager和MHA Node组成。MHA Node运行在需要故障切换/恢复的MySQL服务器上,因此并不需要额外增加服务器。MHA Manager运行在特定的服务器上,因此需要增加一台(实现高可用需要2台),但是MHA Manager可以监控大量(甚至上百台)单独的master,因此,并不需要增加大量的服务器。即使在一台slave上运行MHA Manager也是可以的。综上,实现MHA并没用额外增加大量的服务。
- 无性能下降 MHA适用与异步或半同步的MySQL复制。监控master时,MHA仅仅是每隔几秒(默认是3秒)发送一个ping包,并不发送重查询。可以得到像原生MySQL复制一样快的性能。
- 适用于任何存储引擎 MHA可以运行在只要MySQL复制运行的存储引擎上,并不仅限制于InnoDB,即使在不易迁移的传统的MyISAM引擎环境,一样可以使用MHA。
3.MHA最佳实践